Anthropic has just released Claude Opus 4.5, and it’s a game-changer for software engineers, enterprises, and anyone working with AI-powered tools. Released on November 24, 2025, this model sets new benchmarks in software engineering, agentic capabilities, and enterprise-grade performance.
If you’re building software, analyzing complex systems, or working with autonomous agents, Claude Opus 4.5 deserves your attention. Here’s everything you need to know.
What Makes Claude Opus 4.5 Special?
Claude Opus 4.5 isn’t just an incremental update-it represents a significant leap in AI capabilities, particularly for technical and complex tasks.
State-of-the-Art Software Engineering Performance
The numbers speak for themselves:
- 80.9% score on SWE-bench Verified - outperforming all competing frontier models
- 10.6% improvement over Sonnet 4.5 on the Aider Polyglot benchmark
- 29% higher performance than Sonnet 4.5 on Vending-Bench
- Superior coding capabilities across 7 out of 8 programming languages
What does this mean in practice? Claude Opus 4.5 can tackle complex software engineering tasks with minimal supervision, understanding ambiguous requirements and reasoning through architectural tradeoffs like an experienced engineer.
Enhanced Reasoning and Problem-Solving
Beyond just writing code, Opus 4.5 excels at:
- Handling ambiguity in requirements and specifications
- Multi-system problem-solving across different domains
- Long-context processing with automatic summarization
- Robust agentic task execution with fewer dead-ends
The model can coordinate multi-agent systems effectively, making it ideal for complex enterprise workflows that require multiple specialized AI agents working together.
The Effort Parameter: Performance on Demand
One of the most innovative features is the new effort parameter (currently in beta). This allows you to customize the tradeoff between performance, latency, and cost:
- Medium effort: Matches Sonnet 4.5 performance using 76% fewer output tokens
- Highest effort: Exceeds Sonnet 4.5 by 4.3 percentage points with 48% fewer tokens
This means you can dial up the computational power when you need maximum accuracy on critical tasks, or dial it down for routine operations to save time and money.
Availability: Now on Major Cloud Platforms
Anthropic’s Direct Offering
Claude Opus 4.5 is available through:
- Claude API (model identifier:
claude-opus-4-5-20251101) - Consumer apps (Claude.ai)
- Three major cloud platforms
Pricing: $5 per million input tokens / $25 per million output tokens
Microsoft Azure Integration
As of November 24, 2025, Claude Opus 4.5 is available in public preview on Microsoft Foundry, GitHub Copilot paid plans, and Microsoft Copilot Studio.
Azure Deployment Details:
- Serverless pay-as-you-go model
- Available in East US2 and Sweden Central regions
- Same pricing: $5 per 1M input tokens, $25 per 1M output tokens
For organizations already invested in the Azure ecosystem, this integration makes adopting Claude Opus 4.5 seamless.
Getting Started with Azure: Navigate to Microsoft Foundry to deploy Claude Opus 4.5 in your preferred region.
Google Cloud Vertex AI
Claude Opus 4.5 is now accessible through Google Cloud’s Vertex AI Model Garden, bringing Anthropic’s most powerful model to organizations leveraging Google Cloud infrastructure.
Vertex AI Integration Benefits:
- Seamless integration with Google Cloud services
- Access through Vertex AI’s unified API
- Enterprise-grade security and compliance
- Pay-as-you-go pricing model
For teams already using Google Cloud for their AI/ML workloads, Vertex AI provides a familiar platform to deploy and scale Claude Opus 4.5.
Getting Started with Google Cloud: Visit the Vertex AI Model Garden to access Claude Opus 4.5 through Google Cloud Console.
Amazon Web Services (AWS) Bedrock
Claude Opus 4.5 is available through Amazon Bedrock, AWS’s fully managed foundation model service, with global cross-region inference across multiple locations.
AWS Bedrock Capabilities:
- State-of-the-art performance on SWE-bench for professional development work
- Advanced vision capabilities for complex visual interpretation
- Generate business documents (spreadsheets, presentations, reports) with professional consistency
- Ideal for finance and precision-critical industries
Enhanced API Features (currently in beta):
- Tool search: Navigate extensive tool libraries effectively
- Tool use examples: Improve accurate task execution
- Effort parameter: Balance performance, latency, and costs by controlling resource allocation
The full Claude family is available on Bedrock, spanning the development lifecycle:
- Opus 4.5: Production systems and lead agents
- Sonnet 4.5: Rapid prototyping
- Haiku 4.5: Lightweight applications
Getting Started with AWS: Access Claude Opus 4.5 through the Amazon Bedrock console or refer to AWS’s launch documentation.
Multi-Cloud Deployment Options
Claude Opus 4.5’s availability across major cloud providers gives you flexibility in choosing the platform that best fits your infrastructure:
This multi-cloud availability ensures you can leverage Claude Opus 4.5 regardless of your existing cloud commitments, and enables hybrid or multi-cloud AI strategies.
Developer-Focused Features
Claude Opus 4.5 introduces several features that software engineers will appreciate:
Advanced Tool Use
- Programmatic Tool Calling: Execute tools directly in Python
- Tool Search: Dynamically discover tools from large libraries
- Tool Use Examples: More accurate calling for complex schemas
These capabilities make it easier to integrate Claude into existing development workflows and toolchains.
Context Management
- Compaction Control: Efficiently manage context during extended agentic tasks
- Long-context summarization: Automatically handle large codebases and documentation
No more worrying about hitting context limits when working with large projects.
Vision Capabilities
Improved computer use and vision capabilities mean Claude Opus 4.5 can:
- Analyze screenshots and UI designs
- Create professional documents, spreadsheets, and presentations
- Maintain consistency across visual and textual content
Real-World Performance Benchmarks
Beyond software engineering, Claude Opus 4.5 excels across multiple domains:
- Tool use (retail scenarios): 88.9%
- Tool use (telecom scenarios): 98.2%
- Computer use tasks: 66.3%
These benchmarks demonstrate that Opus 4.5 can handle diverse enterprise scenarios, from customer service automation to complex workflow orchestration.
Community Perspectives: What Developers Are Saying
While benchmarks tell an important story, real-world developer experiences provide valuable context. Early adopters have shared mixed but largely positive feedback about Claude Opus 4.5.
Production Economics: A Surprising Finding
One of the most intriguing observations challenges conventional wisdom about model pricing. A developer running production workloads discovered that Opus 4.5 costs less than Sonnet for many usage patterns-$1.30 per thread versus $1.83 for Sonnet.
This reverses the typical assumption that “cheaper” models always cost less in practice. The key difference? Token efficiency. When a more capable model completes tasks with significantly fewer tokens, the higher per-token price becomes irrelevant. For complex workflows where Opus can solve problems in one pass while Sonnet requires multiple iterations, the economics favor the premium model.
Accessibility Breakthrough
The removal of usage caps has fundamentally changed how developers view Opus. Previously relegated to “important tasks only,” Opus 4.5 is now viable for production workloads at scale. This shift from a premium, rate-limited resource to an unrestricted production tool represents a significant accessibility improvement.
Real-World Architectural Patterns
Developers report success using Opus 4.5 in sub-agent architectures for codebase management. The pattern: Opus handles heavy context processing and complex reasoning, then passes condensed results to lighter agents. This hierarchical approach leverages Opus’s strengths while managing costs effectively.
The Controversy: Performance Consistency
Not all feedback is uniformly positive. Some developers report experiencing performance variability over time, describing scenarios where initially excellent outputs later degraded. One user characterized later results as “a nightmare” compared to earlier outputs.
However, this observation sparks debate within the community. Critics argue these experiences reflect:
- Statistical regression to the mean: Exceptionally good initial results followed by more typical performance
- Natural variability in non-deterministic systems: LLMs inherently produce variable outputs
- Confirmation bias: Bad results are more memorable than consistent good performance
The counterargument: if performance truly degraded, wouldn’t benchmarks catch it? Anthropic maintains consistent model quality through their deployment practices.
Questions About The Speed-Cost Tradeoff
The 3x price reduction combined with 2x speed improvement raises eyebrows in some technical circles. Skeptics speculate this might indicate:
- A smaller underlying model
- Aggressive quantization
- Infrastructure optimizations that trade quality for speed
However, benchmark results appear to contradict these concerns, showing Opus 4.5 outperforming its predecessors across multiple domains. The more likely explanation: significant improvements in model architecture and training efficiency.
The Token Waste Reality
One consistent criticism across AI models generally (not specific to Opus): Claude “wastes about 2-3x more tokens by default” compared to competitors. This verbose tendency means per-token pricing comparisons can be misleading. A model might have lower per-token costs but generate significantly more tokens to accomplish the same task.
This makes the earlier cost-efficiency observation more impressive-despite being chattier, Opus 4.5’s superior reasoning appears to more than compensate through reduced iteration.
What This Means For You
These community perspectives suggest:
- Test with your workload: Per-token pricing is less important than total cost per task
- Monitor long-term performance: Track whether quality remains consistent over weeks and months
- Leverage sub-agent patterns: Opus excels as a “heavy lifter” in hierarchical agent systems
- Start with production mindset: Unlike previous Opus versions, 4.5 is designed for unrestricted production use
The mix of enthusiasm and skepticism is healthy-it reflects a community taking these tools seriously and demanding consistent, reliable performance rather than accepting marketing claims uncritically.
Enterprise Use Cases
Claude Opus 4.5 is particularly well-suited for:
Software Development
- Autonomous coding with minimal supervision
- Architecture planning and design decisions
- Code review and refactoring at scale
- Multi-language development projects
Financial Analysis
- Processing regulatory documents and market data
- Complex financial modeling
- Risk assessment across multiple data sources
- Compliance analysis
Cybersecurity
- Threat detection and response
- Security audit automation
- Vulnerability assessment
- Incident response coordination
Enterprise Automation
- Multi-step workflow automation
- Cross-system integration tasks
- Document processing and analysis
- Customer support escalation
Security and Alignment
Anthropic emphasizes that Claude Opus 4.5 is their most robustly aligned model yet, featuring:
- Strong resistance to prompt injection attacks
- Enhanced safety measures for enterprise deployment
- Reliable behavior in autonomous scenarios
This makes it suitable for production environments where security and predictable behavior are critical.
How It Compares to Other Models
Claude Opus 4.5 stands out among frontier AI models with impressive benchmark results across multiple categories:
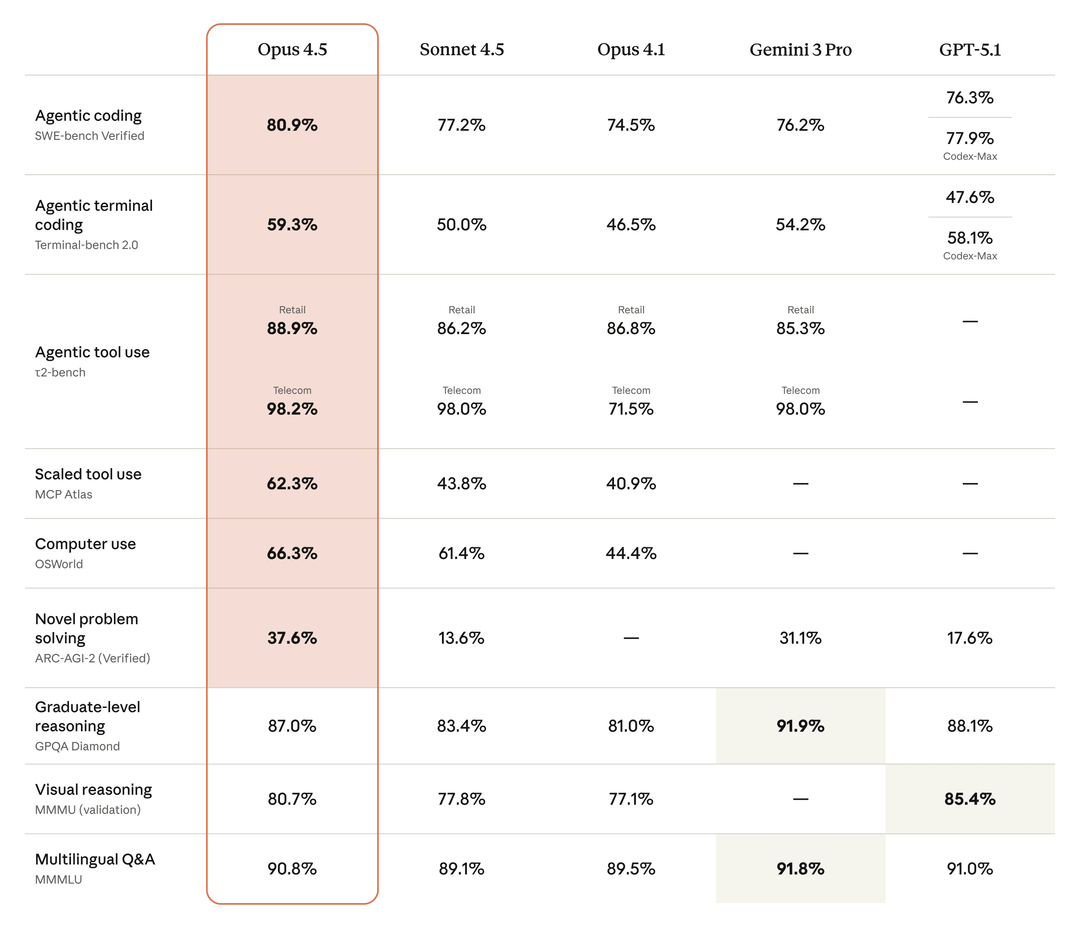
While specific head-to-head comparisons depend on your use case, Claude Opus 4.5 distinguishes itself through:
- Software engineering excellence: Leading performance on SWE-bench Verified
- Efficiency: Significantly fewer tokens needed for comparable or better results
- Agentic capabilities: Reduced dead-ends and better multi-step reasoning
- Enterprise focus: Built for production deployment with strong alignment
The effort parameter also provides flexibility that other models lack-you can optimize for speed when prototyping and dial up accuracy for production code.
Getting Started
For Individual Developers
- Access Claude Opus 4.5 through Claude.ai
- Use the API with model identifier:
claude-opus-4-5-20251101 - Experiment with the effort parameter to find your optimal balance
For Azure Users
- Navigate to Microsoft Foundry
- Select Claude Opus 4.5 from the model catalog
- Deploy in East US2 or Sweden Central regions
- Integrate with GitHub Copilot or Microsoft Copilot Studio
For Enterprises
Consider Claude Opus 4.5 for:
- High-stakes coding tasks requiring maximum accuracy
- Complex multi-agent workflows
- Financial and regulatory analysis
- Cybersecurity operations
The pay-as-you-go pricing model means you can start small and scale as needed.
Why This Release Matters
Claude Opus 4.5 represents a significant milestone in AI capability for several reasons:
Pushing Software Engineering Boundaries
The 80.9% score on SWE-bench Verified isn’t just a number-it represents AI that can handle real-world software engineering tasks that previously required human expertise.
Economic Efficiency
By achieving better results with fewer tokens, Opus 4.5 makes advanced AI more economically viable for production use. The effort parameter ensures you’re not paying for maximum performance when you don’t need it.
Enterprise Readiness
Strong alignment, security features, and integration with major cloud platforms signal that advanced AI is ready for serious enterprise deployment, not just experimentation.
Democratizing Expertise
When an AI model can analyze complex financial data, detect security threats, and write production-quality code, it democratizes access to specialized expertise-potentially transforming how organizations operate.
The Bottom Line
Claude Opus 4.5 is Anthropic’s most powerful and capable model yet, with clear strengths in:
- Software engineering and coding tasks
- Agentic and autonomous workflows
- Complex reasoning and problem-solving
- Enterprise-grade security and reliability
With availability on major cloud platforms and competitive pricing, it’s accessible to organizations of all sizes.
Whether you’re building autonomous coding agents, automating complex workflows, or need AI assistance for specialized analytical tasks, Claude Opus 4.5 is worth evaluating for your use case.
The combination of raw capability, economic efficiency through the effort parameter, and enterprise-ready features makes this release particularly significant. As AI continues to evolve, models like Claude Opus 4.5 are setting new standards for what’s possible.
Learn More
Have you tried Claude Opus 4.5 yet? What use cases are you most excited about? The combination of advanced capabilities and flexible performance tuning opens up fascinating possibilities for software engineering and enterprise automation.